
GRPO on MathVista with Unsloth
What Are We Solving?
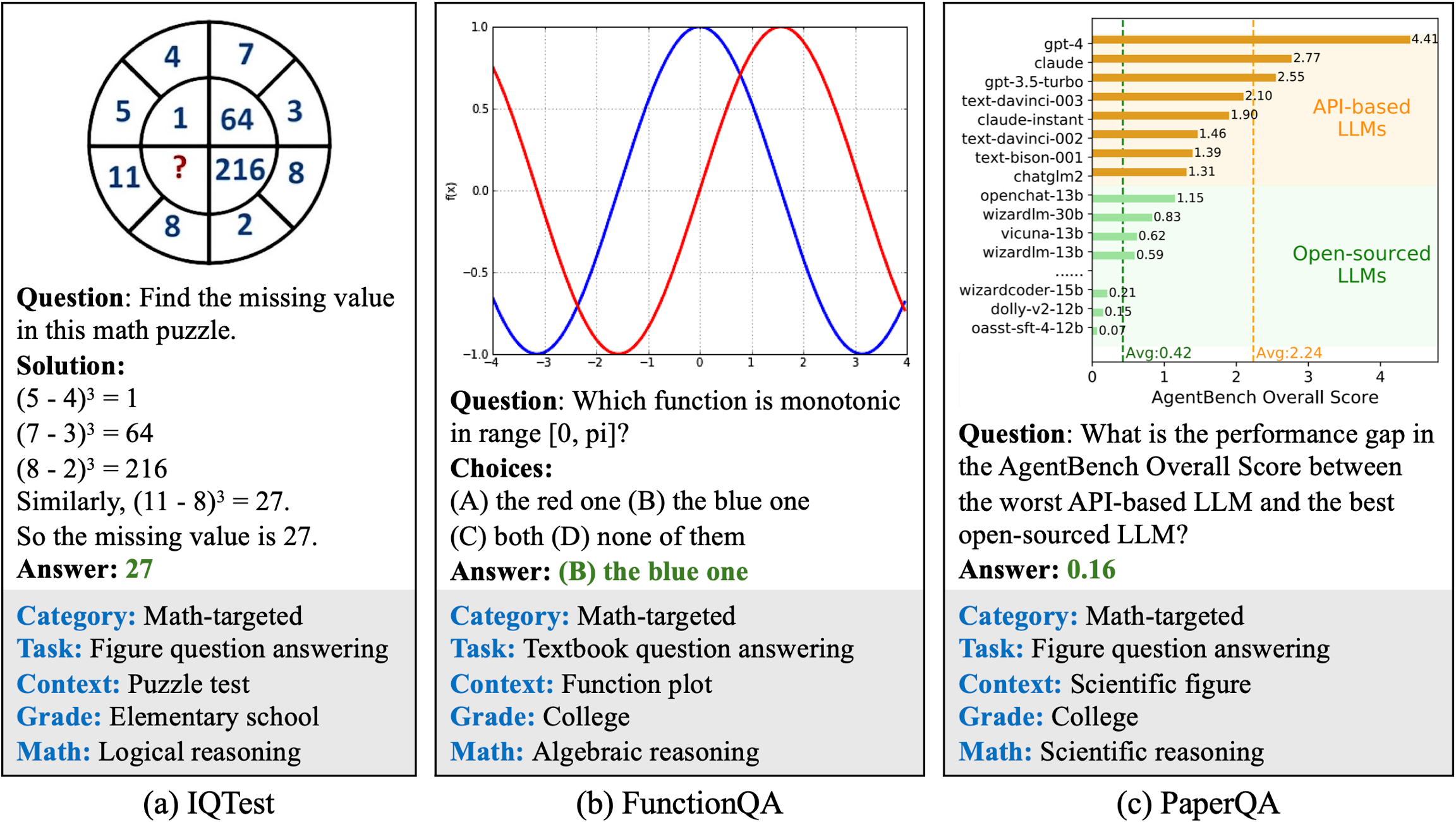
Why GRPO on a VLM?
Method
Needs reasoning traces?
Sample efficiency
Section 1 — YottaLabs Platform
Section 2 — Environment Setup
Section 3 — Load Qwen3-VL 8B with QLoRA
Key Parameters Explained
Parameter
Value
Why
Attach LoRA Adapters
Section 4 — Prepare the MathVista Dataset
Data Pipeline
Why 512×512?
Section 5 — Design Reward Functions
Reward 1 — Format Compliance (formatting_reward_func)
formatting_reward_func)Condition
Points
Reward 2 — Correctness (correctness_reward_func)
correctness_reward_func)Condition
Points
Total Reward Range: −2.0 to +4.0
Section 6 — Pre-Training Baseline Inference
Section 7 — Configure & Launch GRPO Training
How GRPO Works (Briefly)
GSPO Extension (Enabled Here)
Key Hyperparameters
Parameter
Value
Effect
Section 8 — Post-Training Inference
Section 9 — Save & Export
Method
File size
Use case
Last updated
Was this helpful?